Gemma 4 QAT on a 16 GB Mac: the E4B matches the 12B at 42% less RAM and 3× the speed
Google’s quantization-aware-trained Gemma-4 E4B matches the full 12B’s math and factual accuracy on an M3 while using 42% less memory and running 3× faster. QAT isn’t a lossy convenience here — on the things I can measure cleanly, it’s a free lunch.
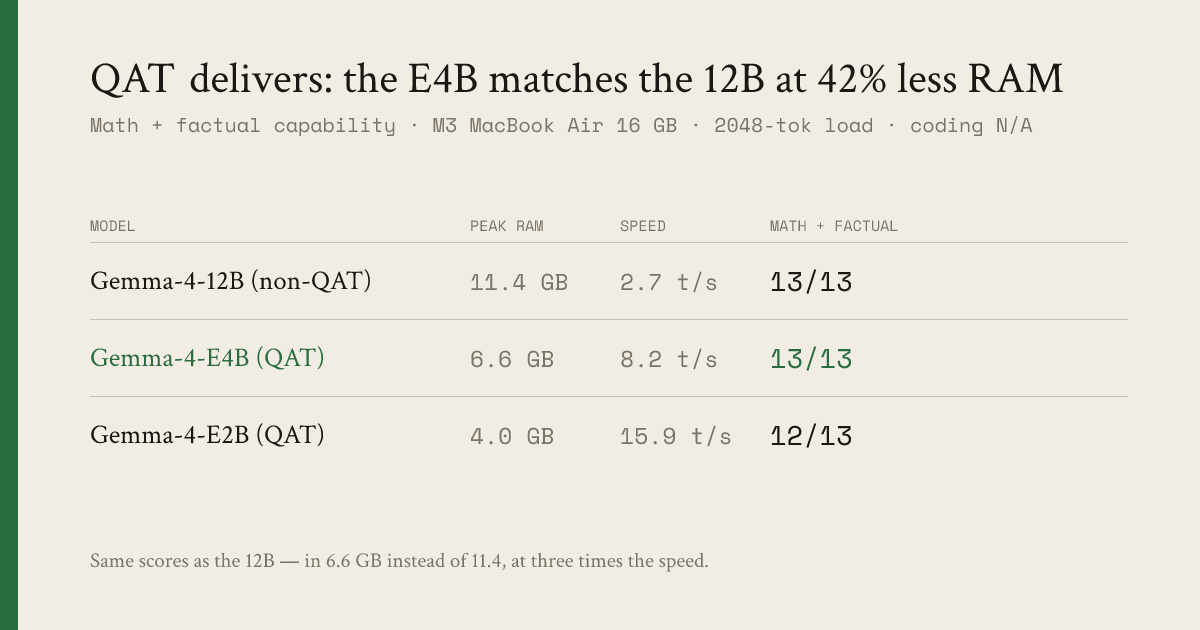
The numbers, all on the same 16 GB MacBook Air, all under a 2048-token load (peak RAM measured in an isolated process so it’s real, not a cumulative-batch artifact):
| Model | RAM (under load) | tok/s | Math | Factual |
|---|---|---|---|---|
| Gemma-4-12B (4-bit, non-QAT) | 11.37 GB | 2.7 | 8/8 | 5/5 |
| Gemma-4-E4B QAT | 6.62 GB | 8.2 | 8/8 | 5/5 |
| Gemma-4-E2B QAT | 4.02 GB | 15.9 | 7/8 | 5/5 |
E4B is the headline: identical math (8/8) and factual (5/5) scores to the 12B, but it fits in 6.6 GB instead of 11.4 — the difference between “this is the only thing my Mac is doing” and “I can keep my editor, browser, and a model open at once.” It also decodes at 8.2 tok/s versus 2.7, which is the line between readable and waiting.
E2B is the speed play: 15.9 tok/s and a 4 GB footprint, giving up exactly one math question. On a 16 GB machine where memory is the binding constraint, that’s a genuinely different operating point.
One honest caveat: I’m reporting coding as N/A, not as a score. Gemma-4 emits its reasoning in a <|channel|>thought format that my code-extractor can’t parse — it writes correct logic, describes the call in prose, and splits candidate blocks across the trace. The number you’d get is a function of how hard the extractor tries, not of the model’s ability, so reporting one would be dishonest. (This is the same class of self-inflicted benchmark bug I wrote about last week — the fix was to stop trusting the extractor, not to tune it.) Math and factual checks read the answer text directly and are trustworthy.
The upshot for 16 GB users: skip the 12B. The QAT E4B gives you the same answers, leaves you 5 GB of headroom, and runs three times faster.